로컬 LLM을 사용하려는 이유?
- 토큰에 대해 걱정을 덜 하면서 모델에 추가적인 지식을 넣되 유출 가능성이 낮으면서도 내부망에 서빙이 가능할까~?
- 토큰에 대해 즉 사용량같은 것들에 대해 걱정을 좀 덜 하면서 모델에 우리 도메인에만 알고 있는 지식을 추가적으로 넣어주면서 유출이 낮은 내부망의 서빙이 가능할까
- 즉 외부로 데이터가 유출되지 않으면서 서비스 하는게 될까 라는 질문
토큰에 대해 걱정을 덜 하면서
GPT-4 기준 1k tokens에 0.04$
모델에 추가적인 지식을 넣되
LM에 추가적인 지식을 넣어주는 Finetune
LLM API도 Fine-tune을 지원 하지만 학습도 비용, Inference는 더 비싼 비용 (OpenAI)
LLM Finetune도 Full Finetune 아닌 일부만 학습
- API로만 사용 가능 (Weight 얻을 수 없음)
교육 도메인이다, 아니면 법률 도메인이다, 아니면 메디컬, 의학 도메인이다 라고 하면은 그런 굉장히 세부적인 정보들은 LM 안에 들어가 있을 수도 있지만 안 들어가 있는 경우가 많다.
유출 가능성이 낮으면서도 내부망에 서빙
법률적인 이슈랑 좀 많이 관련이 돼 있죠.
고객들의 데이터가 웹 제3자에게 넘어가면 안 된다는 개인정보 보호부터 시작해서 그런 여러 가지 이슈들
알파카 : 인스트럭션을 팔로잉 하는 LLM
❇️ 인사이트 → LLM은 이미 수많은 정보를 알고 있다 (Pretrained LLM 은 이미 세상에 대한 굉장히 많은 지식이 이미 내포가 되어 있다) 수많은 지식이 내포가 되어 있는데 단순히 어떻게 말을 해야 될지 몰라서 이말 저말 다 쏟아내고 있을 뿐이다…!
말을 이어쓰는거랑 명령어를 따르는 게 어떻게 다르냐
단순히 말을 이어쓰는 거랑 명령을 따르는 거랑 이 두 개의 모델이 다르고 이 명령어를 따르는 걸 통해서 좀 더 우리가 활용하기 좋은 좀 더 가치가 있는 언어모델을 만들어준 것
- 기존에 있던 언어모델이 명령어를 따를 수 있는 능력을 갖게 하는 명령어를 따르는 데이터셋을 만들고 모델 학습
- 추가적으로 데이터셋에 없었는데 모델 내부의 지식을 친절하고 긴 답변의 형태로 답을 할 수 있도록 얼라인먼트
- 추가적으로 추가적인 맥락을 참조할 수 있도록 얼라인먼트 (노이즈를 무시하고 거기서 중요한 데이터를 추출해가면서 깔끔한 답변을 생성해주는 능력) 즉 추가적인 맥락을 보고서 답변을 할 수 있는 능력이 생긴 것
- 방향성 → 얼라인먼트 -> 뉘앙스 (즉 모델한테 특정 테스크를 학습할때 [self-consistency](https://feel2certainty.tistory.com/32) 능력을 부여한다 던지, step by step 생각할 수 있는 능력을 부여하는 방식으로 학습해서 ) 파인튜닝 모델이 chatGPT처럼 뉘앙스를 파악하고 동작할 수 있게 방향성을 알려주는 것임..!
- 모델의 크기가 100 빌리언만큼 크지는 않다고 하더라도 좋은 파인튜닝 데이터, 즉 어떤 방향성을 최대화해서 모델에서 그것을 끌어낼 것인지 방향성을 잘 잡아주는 그런 파인튜닝 데이터가 있으면, 그 방향성에 대한 능력을 넣어줄 수 있다는 것을 알게됨
- 모델의 규모가 100 빌리언 정도의 크기에 이르지 않더라도, 우리는 매우 효과적인 파인튜닝 데이터 세트를 통해 그 방향성을 모델에 학습시킴으로써 모델의 해당 능력을 강화시킬 수 있다는 점을 인식하게 되었다.
- 이것은 구체적인 지향점을 설정하고, 그 방향으로 모델을 조정하는 역할을 하는 데이터 세트의 중요성을 강조한다.
LLM 모델 학습
< 100B 이내의 작은? LLM
장점
- GPT-4 급은 아니어도 어느 정도 나오는 성능
- 도메인 지식을 추가로 학습시킬 수 있음
- 모델의 성능을 꾸준히 개선시킬 수 있음
단점
- 개선되었지만, 100B 이상 LLM 보다는 낮은 성능
- Domain 관련 Text 필요(Domain Adaptation)
- AI 연구/개발 인력 필요
- 서빙에 대한 고려가 필요, 특히 GPU 서빙에 대한 진지한 고려가 필요함
학습 데이터
- 1.2 TB정도 초거대 한국어 코퍼스 제작

Polyglot-Ko 모델 학습 소요 기간
- 1.3B : 213B 토큰을 102,000 스텝 동안 학습시켰음 (약 1~2주 소요)
- 3.8B : 218B 토큰을 105,000 스텝 동안 학습시켰음 (약 2~3주 소요)
- 5.8B : 172B 토큰을 320,000 스텝 동안 학습시켰음 (약 3~4주 소요)
- 12.8B : 167B 토큰을 300,000 스텝 동안 학습시켰음 (약 7~8주 소요)
GPU 사용 승인 (Eluther AI)
- 512개의 A100 GPU
학습 비용

A100이나 TPU 같은 고가의 장비로 학습을 하는데 공개되어 있는 폴리글랏 코리안 5.8밀리언 모델 같은 경우에 A100 256대로 수십 수일간 학습 (약 3~4주)
- 비용 대략 3~4억
데이터셋 있는 건 좋은데 우리가 갖고 있는 데이터셋이 정말로 유의미하게 충분히 많고 충분히 잘 정제되어 있고 그리고 이 컴퓨팅 파워 하루에 천만원, 몇천만원 쓰는 비용도 감당할 만하다라고 결정이 되어야 프리트레인을 시작을 할 수가 있음
LLM 성능
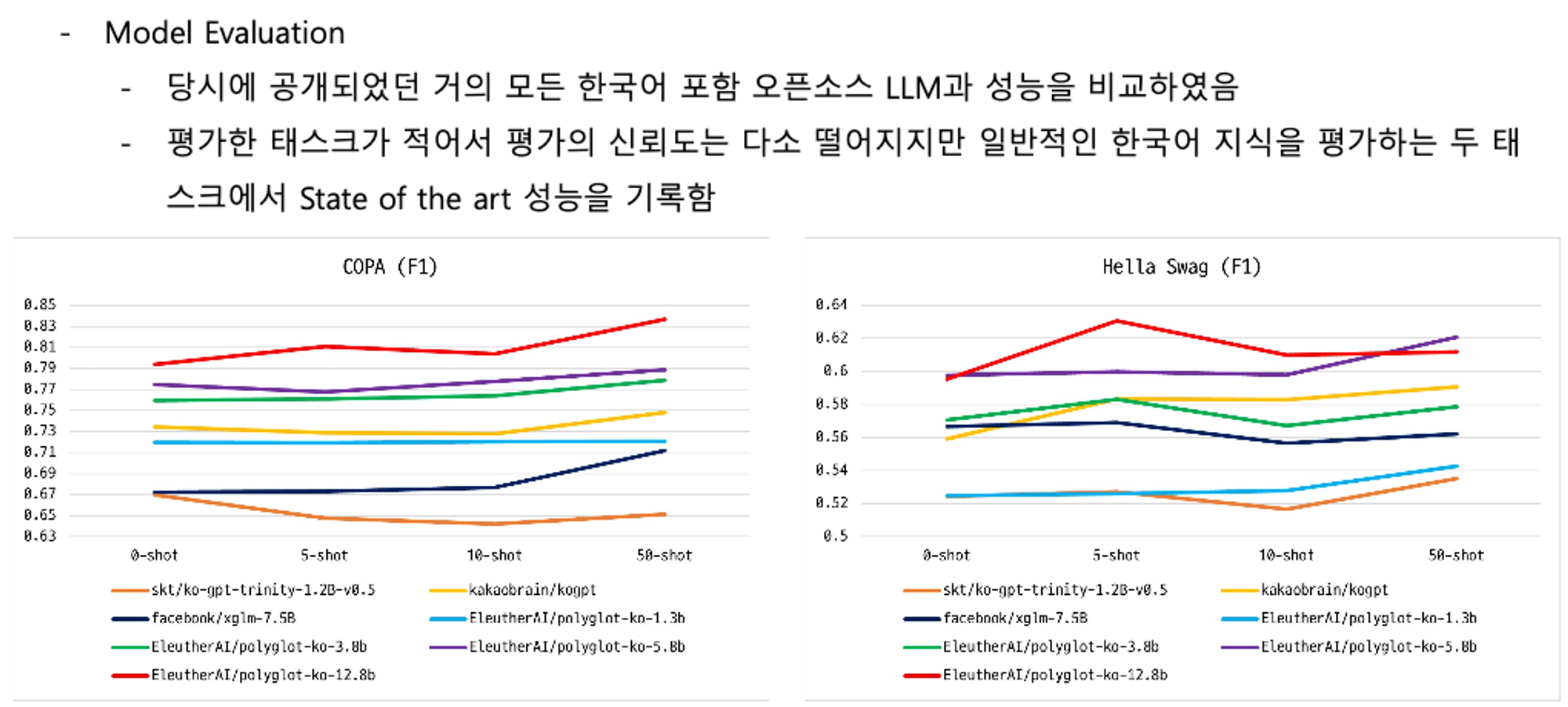
https://aclanthology.org/2022.coling-1.325/
KoBEST: Korean Balanced Evaluation of Significant Tasks
Myeongjun Jang, Dohyung Kim, Deuk Sin Kwon, Eric Davis. Proceedings of the 29th International Conference on Computational Linguistics. 2022.
aclanthology.org
SKT에서 만든 코베스트라는 평가 데이터 세트에서 프롬프트까지 같이 제공

finetuning
- KoAlpaca-Polyglot(5.8B, 한국어) Full Finetune: A100 80GB 1장, 약 ~6시간
- KoAlpaca 7B(LLAMA, 영어기반) Full Finetune: A100 80GB 4장, 약 ~4시간
- KoAlpaca LLAMA 13B LoRA: RTX 3090(24GB) 4장, 약 ~24시간
- KoAlpaca LLAMA 30B LoRA: A100 40GB 4장, 약 ~24시간
- KoAlpaca LLAMA 65B LoRA: A100 80GB 8장, 약 ~36시간
대부분의 학습은 Seq len 1024로, 3epochs정도 학습
리소스 사용의 경우 별도의 페이퍼는 없지만, LoRA 논문( https://arxiv.org/abs/2106.09685 )와 lora alpaca 레포등을 참고하면서, GPU가 허용하는 한도 내 최대의 batch size를 사용
A100이나 H100으로 파인튜닝을 해주는 방법

Polyglot 모델이나 아니면 Polyglot-Ko 모델들 5.8B 아니면 12.8B 이미 사전에 잘 학습되어 있는 모델들이 있다 보니까 이것들을 코알파가 같이 공개된 데이터셋 혹은 자체적으로 제작한 데이터셋으로 파인튜닝만 시켜줘도 성능이 어느 정도 나오는 걸 볼 수 있음
대표적으로 5.8빌리언 폴리글랏 같은 경우는 A100 80기가짜리 한 대로 수시간에서 한 12시간 정도까지 최대 12시간 정도 학습하면 조금 비싼 GPU을 쓴다고 하더라도 5만원이고 사실 정말로 싼 곳에서 하면 2만원 안쪽으로 학습을 마칠 수가 있음
12.8B 처럼 더 큰 모델을 학습한다고 하더라도 어떻게 보면은 12시간 내로 몇 대만 쓰면 되니까 수십만원 안쪽 선으로 맞춘다라고 보여서 현실적인 수준이라고 볼 수 있음


참조
https://www.youtube.com/watch?v=vzbGNxzYW0A
'Machine Learning > DL - NLP' 카테고리의 다른 글
| ChatGPT 창의성과 정확도를 높이는 3가지 방법으로 GPT를 커스터마이징 하세요! (0) | 2024.01.27 |
|---|---|
| PEFT 기법 (LoRA, IA3) (0) | 2023.07.07 |
| 구글 PaLM 2 정리 (0) | 2023.06.27 |
| KoAlpaca 랭체인(langchain) 활용하기 (0) | 2023.06.13 |
| Chroma(Vector DB) and Sentence Transformer (0) | 2023.05.30 |

댓글